まず一言で
結論: サンプルサイズは「相場」ではなく「問い」から決まる。検出したい差、測定ノイズ、許容する誤判定、必要な信頼区間の幅、対応あり/なし、外部検証の有無を決めて、初めて必要なn数を議論できる。
MRI研究では、症例を集めるコストが高く、撮像条件、装置差、読影者差、セグメンテーション差、再構成条件が結果に影響します。だからこそ、n数は「なんとなく30」ではなく、研究の目的に合わせて設計する必要があります。
この記事の立ち位置
公開文献と一般的な統計原理にもとづく教育用記事です。個別研究の正式な統計解析計画書ではありません。実際の研究では、主要評価項目、解析単位、欠測、脱落、倫理要件、施設差、外部検証を専門家と確認してください。

n=30神話を外す
n=30は、中心極限定理や実務上の目安と混ざって語られがちですが、MRI研究の十分性を保証する数字ではありません。2群比較、一致性評価、診断性能、AIモデル、reader study、再構成評価では、必要なnの考え方が異なります。
相場としてのn
同じ分野の論文がどの程度のnで行われているかを知ることは有用です。ただし、それは「同じnなら妥当」という意味ではありません。
設計としてのn
検出したい差、ばらつき、許容誤差、信頼区間の幅、外部検証の有無から決めます。こちらが本当のサンプルサイズ設計です。
power計算: 差・SD・α・powerの関係
2群の平均差を検出したい場合、直感的には「差が大きいほど少ないnでよい」「ばらつきが大きいほど多いnが必要」「より厳しい有意水準、より高い検出力を求めるほど多いnが必要」です。
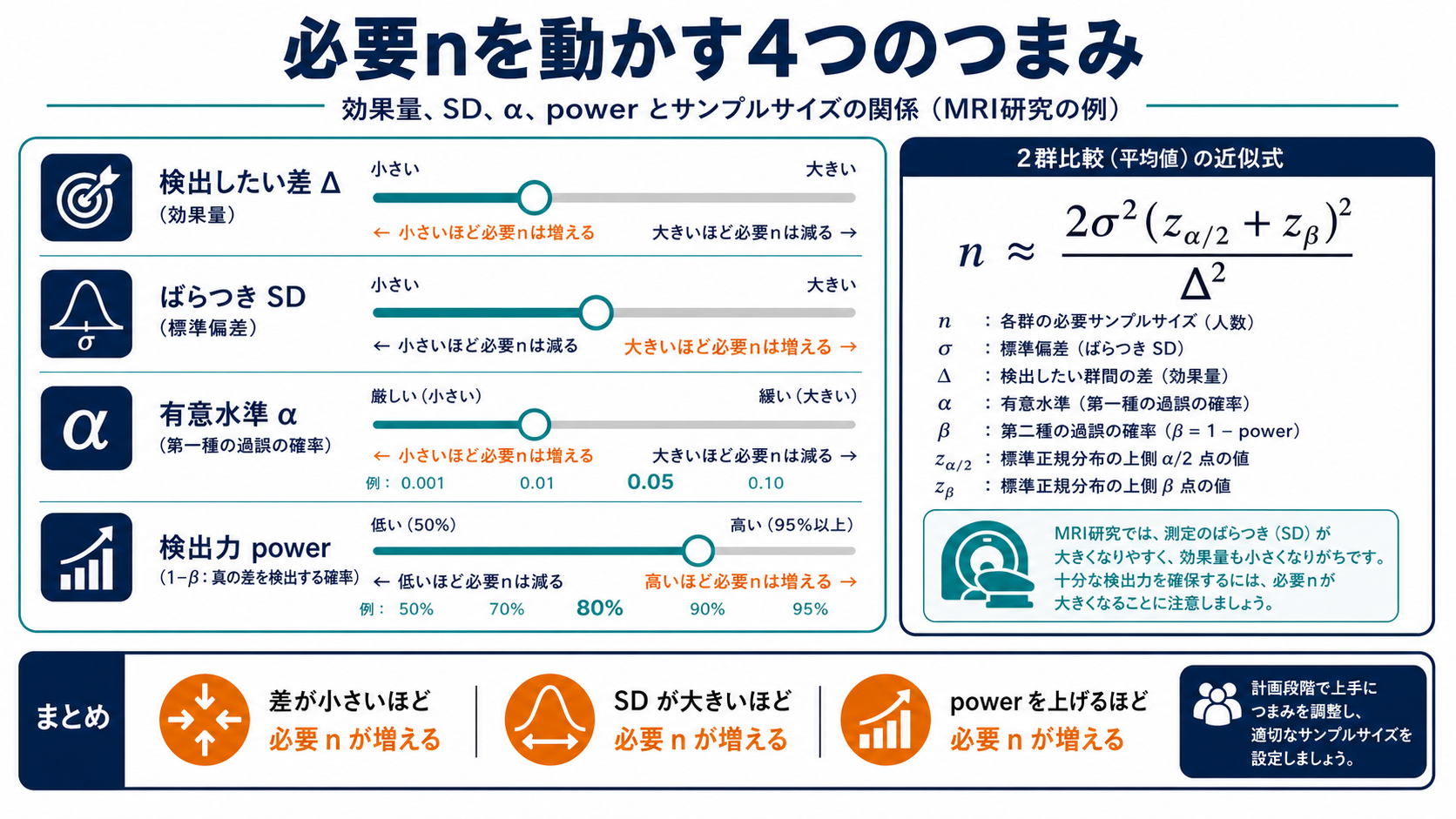
各群に必要な目安数。独立2群の平均差を想定した近似。
検出したい差。小さい差を検出したいほど必要nは増える。
測定値のばらつき。MRIでは撮像条件、解析条件、対象の多様性で変わる。
第一種過誤。通常は0.05が多いが、多重比較では調整が必要。
第二種過誤β、検出力は1-β。80%や90%がよく使われる。
正規分布の分位点。厳しい条件ほど式の分子が大きくなる。
数式が苦手な人向け: この式は「差をノイズから浮かび上がらせる」式
Δは見つけたい信号、σは背景のばらつきです。Δが大きい研究は、少ないnでも差が見えます。σが大きい研究は、差がノイズに埋もれるので多いnが必要です。
この式は独立2群の単純化です。対応あり比較、非正規データ、割合、AUC、ICC、Bland-Altman、AIモデルでは別の設計が必要です。
MRI研究のn数相場: ただし十分性ではない
2025年の臨床MRI研究734本の調査では、全体の中央値は74.5例、前向き研究は41例、後ろ向き研究は129例でした。50.5%が75例未満、90.3%が350例未満、1000例超は1.6%だけです。
多施設研究は全体の10.6%で、中央値は単施設64例に対して多施設240例でした。評価方法別ではMachine learningが226例、Radiomicsが180例と高めでした。これは「相場」として参考になりますが、十分なpowerや外部検証を保証するものではありません。
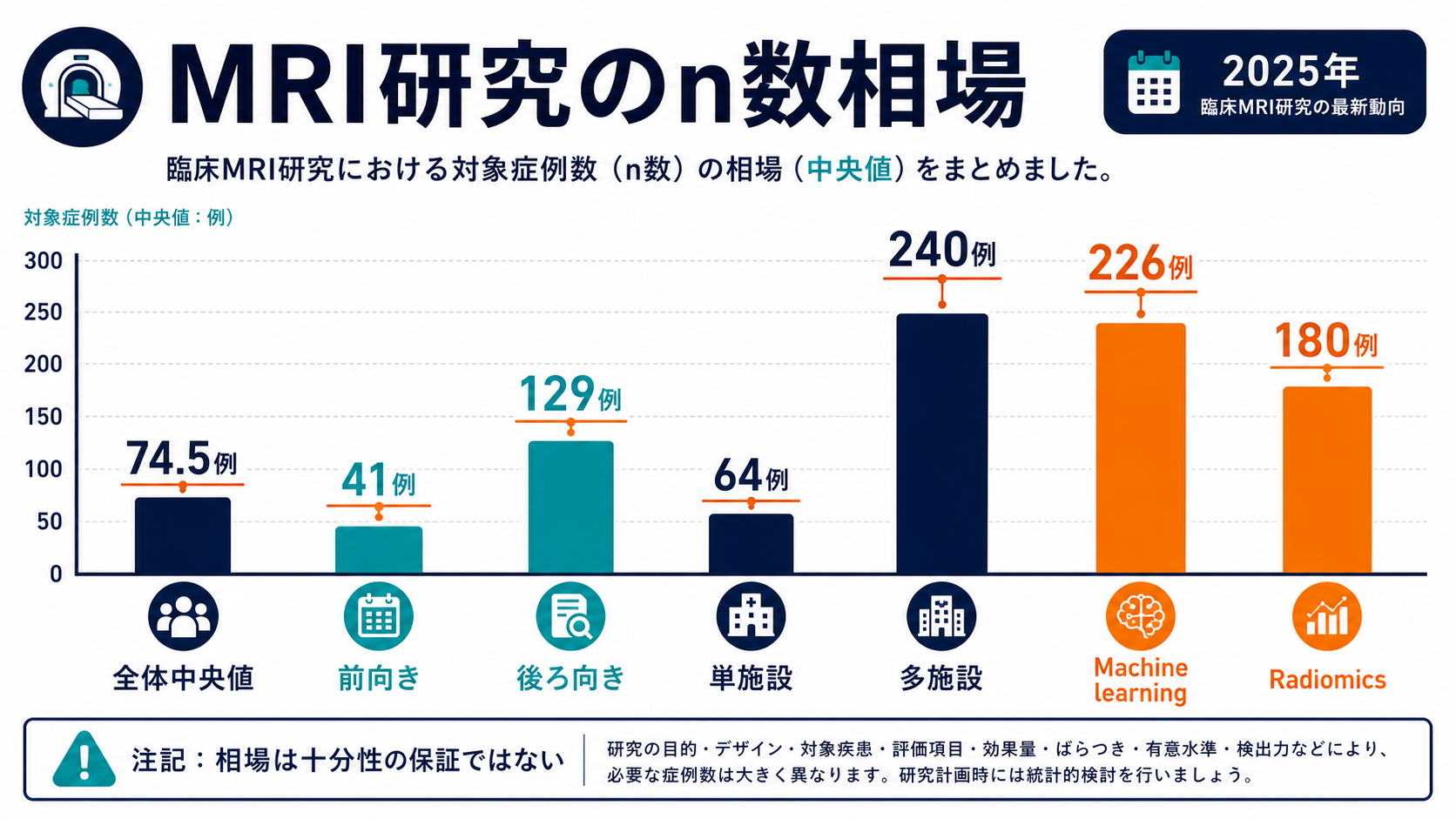
相場と妥当性を混同しない
分野の中央値に近いから妥当、という判断は危険です。効果量が小さい研究、測定ノイズが大きい研究、外部検証が必要な研究では、相場より多いnが必要になることがあります。
対応ありデザイン: 同じ対象を使う強さ
同じ対象で前後、左右、2条件、2再構成を比べる場合、対象間のばらつきを差し引けるため、独立2群より少ないnで差を検出できることがあります。鍵になるのは「差のSD」です。
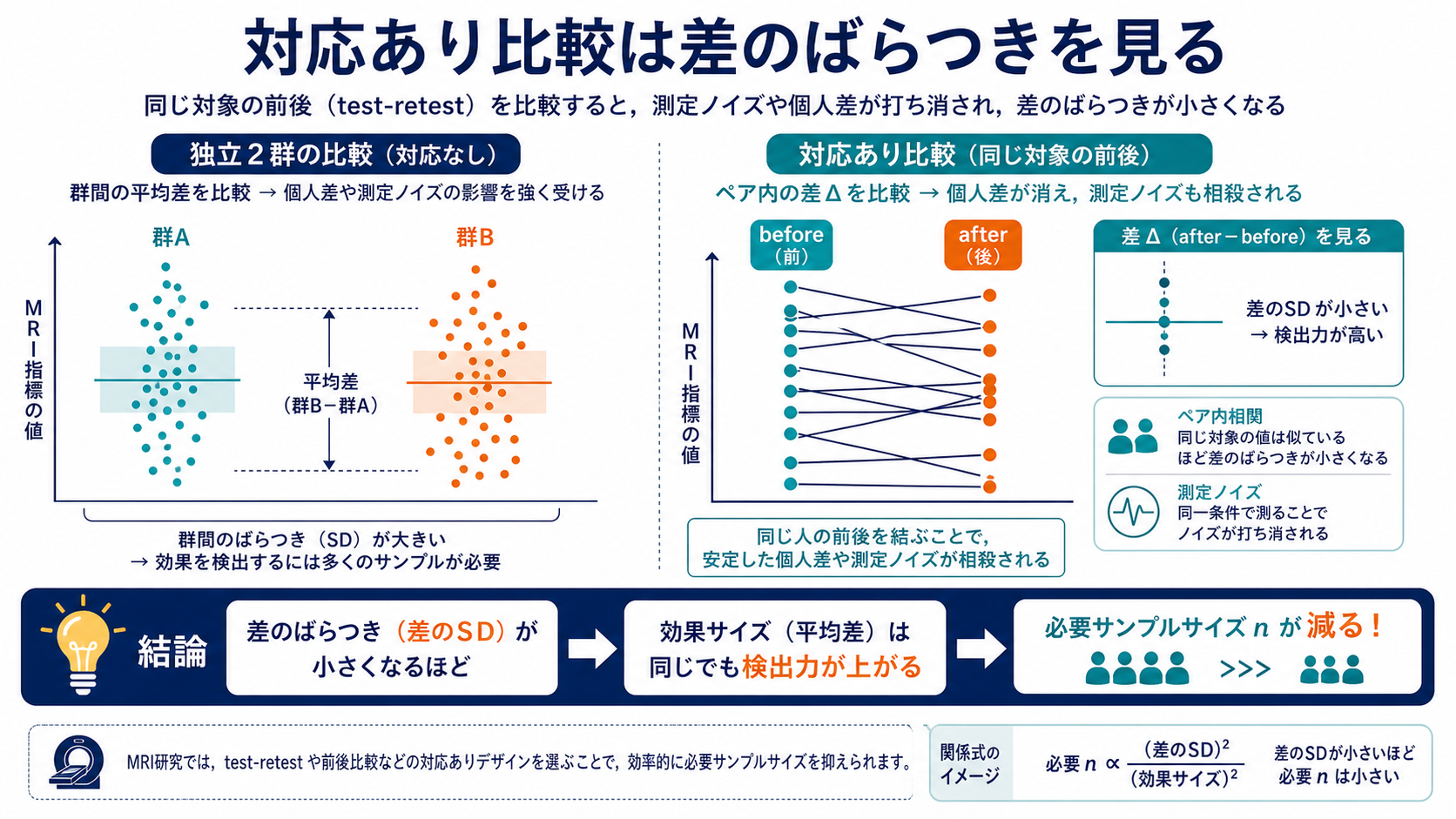
ペア差のSD。対象ごとの差のばらつき。
検出したい平均差。before/afterや2再構成間の差。
4D Flowの再構成法比較、同一データへの解析法比較、test-retest、読影者間比較では、対応あり構造を保った解析にすると効率が上がります。ただし、ペアが崩れる欠測や時相差があると、その利点は弱くなります。
研究タイプ別: 何を基準にnを考えるか
| 研究タイプ | n数の考え方 | 代表的な統計・評価 |
|---|---|---|
| 2群比較 | 検出したい差、SD、α、power | t検定、Mann-Whitney U検定、効果量、95%CI |
| 対応あり比較 | 差のSD、ペア内相関、欠測 | 対応ありt検定、Wilcoxon符号付順位検定、混合効果モデル |
| 3条件以上 | 独立か反復測定か、事後比較数 | ANOVA、Kruskal-Wallis、反復測定ANOVA、Friedman検定 |
| 定量値の一致 | 許容誤差、LoAの精度、test-retest構造 | Bland-Altman、ICC、repeatability coefficient |
| 診断性能 | 陽性/陰性それぞれの数、期待AUC、閾値 | ROC/AUC、感度、特異度、PPV、NPV |
| reader study | 症例数だけでなく読影者数、読影条件 | MRMC、kappa、ICC、AUC比較 |
| AI/radiomics | training/validation/test、イベント数、外部検証 | AUC、calibration、decision curve、外部検証 |
| 再構成・unwrapping | ground truth、phantom、simulation、in vivoの役割分担 | RMSE、residual aliasing、flow bias、VNR、TKE error |
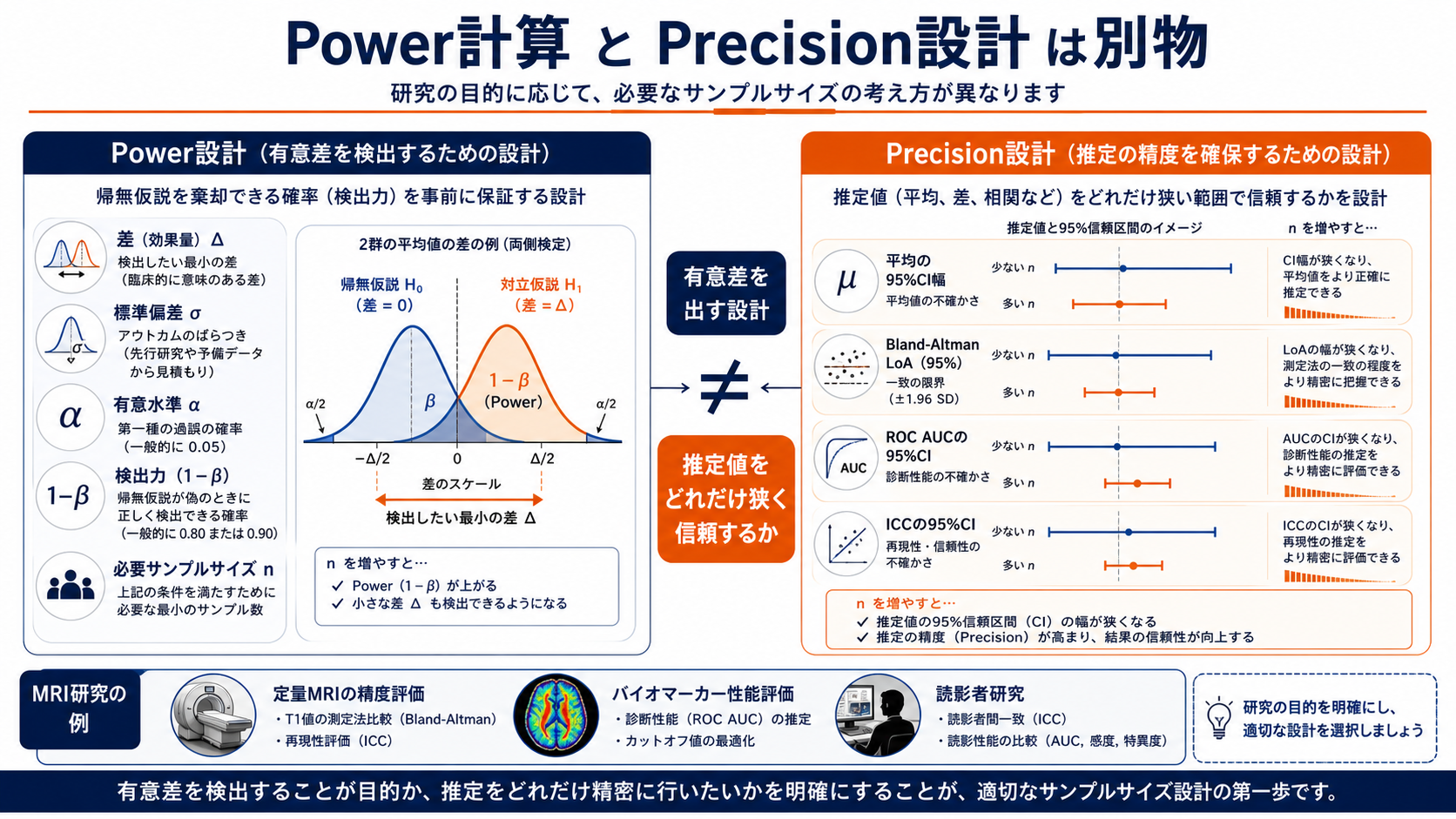
Bland-Altman / ICC / ROC: powerではなくprecisionを見る
一致性や診断性能の研究では、「差が有意か」よりも「どれくらいの精度で推定できるか」が重要になります。Bland-Altmanならbiasと95%一致限界、ICCなら信頼区間、ROCならAUCと感度・特異度の信頼区間を読みます。
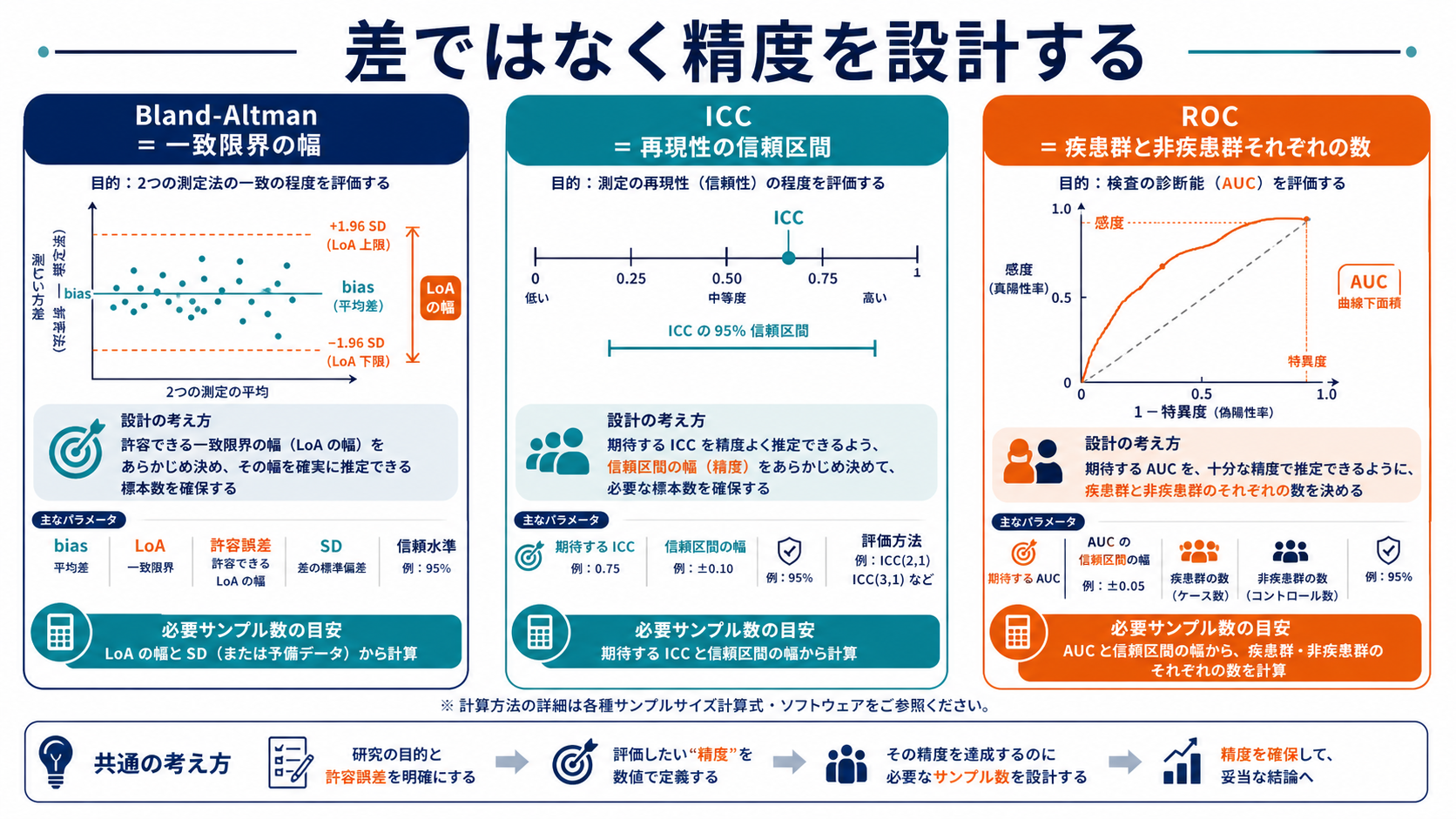
Bland-Altman
biasが小さいだけでなく、95%一致限界が許容範囲に収まるかを見る。LoAの信頼区間が広すぎると、置き換え可能性を判断しにくい。
ROC/AUC
AUCだけでなく、陽性例と陰性例のバランス、閾値での感度・特異度、外部検証での性能低下を見る。
AI/radiomics: 小さいnで高性能に見える罠
AIやradiomicsでは、特徴量数が多く、モデル選択の自由度も大きいため、小さいnでは過学習が起こりやすくなります。trainingで高い性能が出ても、validation、test、外部検証で落ちることがあります。
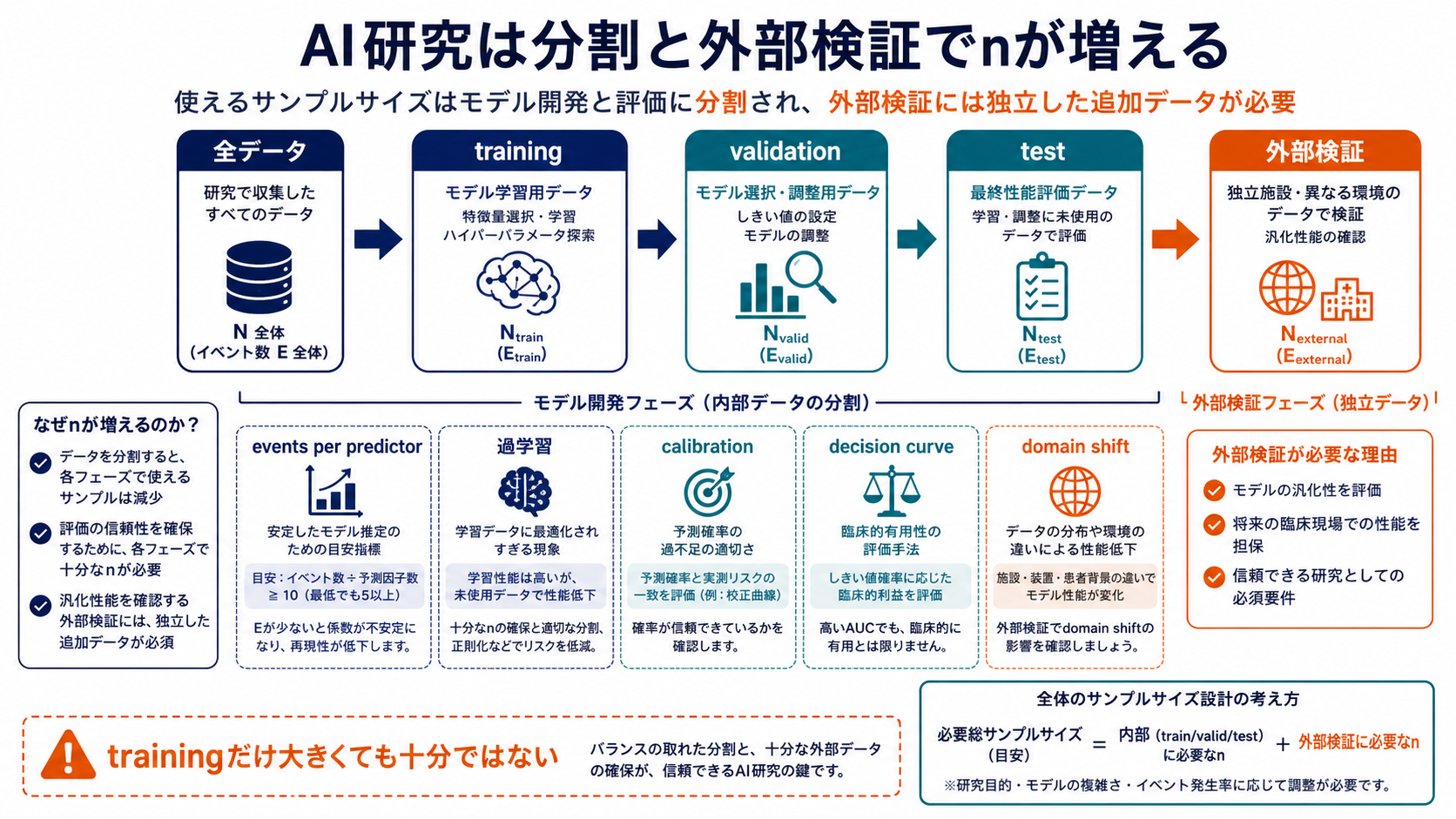
2025年のradiomics研究メタリサーチでは、116本中、サンプルサイズの正当化があったのは11本、そのうち事前計算を行っていたのは6本でした。中央値は全体223例、training 150例で、多くの研究が過学習を避けるには小さすぎる可能性があると指摘されています。
AI評価で最低限見るもの
データ分割、外部検証、イベント数、欠測処理、特徴量選択のタイミング、ハイパーパラメータ、calibration、decision curve、failure caseを確認します。AUCだけで研究の強さを判断しないことが重要です。
4D Flow再構成・unwrapping評価のn設計
Multi-VENC、phase unwrapping、Bayesian unfolding、Deep Learning補正では、単純な症例数だけでなく、ground truthの階層を設計します。simulation、flow phantom、in vivo、高VENC reference、それぞれの役割が異なります。

| 評価層 | 強み | 限界 | 見る指標 |
|---|---|---|---|
| simulation | true velocityを知っている | 実データの複雑さを完全には再現しない | RMSE、aliasing残存、TKE error |
| flow phantom | 条件を制御できる | 臓器運動や複雑な背景信号が少ない | flow bias、VNR、再現性 |
| in vivo | 実臨床に近い | true valueが不明になりやすい | 残存折り返し、視覚QC、流量整合、reader評価 |
| 外部データ | 一般化性能を見られる | 撮像条件差、施設差、装置差の影響 | 性能低下、failure case、domain shift |
深掘り: 4D Flowでは「n」より「aliasing severity分布」も重要
速度の折り返し補正では、対象数だけでなく、peak velocity/VENC比、折り返しvoxel割合、低VNR領域、複雑流、segmentation error、motionをどれだけ含めたかが効きます。
同じnでも、簡単なケースだけを集めた研究と、failure-proneなケースを含む研究では、評価の意味が大きく違います。
文献紹介
2025年の臨床MRI研究n数調査
734本の臨床MRI研究を調べ、全体中央値74.5例、前向き41例、後ろ向き129例、多施設240例、Machine learning 226例、Radiomics 180例など、MRI研究のn数相場を示した実務的に有用な調査です。
fMRI研究のサンプルサイズ報告レビュー
観察fMRI研究でサンプルサイズ計算やpower計算に必要な情報が十分に報告されていない問題を示したレビューです。相場ではなく、設計と報告の透明性が重要であることを教えてくれます。
Radiomics研究のサンプルサイズ問題
Radiomics研究では、特徴量数やモデル選択の自由度に対してnが小さく、サンプルサイズ正当化が不足しやすいことが示されています。AI/radiomics評価では外部検証と過学習対策が不可欠です。
- Analysis of the sample size used in clinical MRI studies. PLOS One. 2025.
- A systematic review of the reporting of sample size calculations and corresponding data components in observational functional magnetic resonance imaging studies. NeuroImage.
- Overlooked and underpowered: a meta-research addressing sample size in radiomics prediction models for binary outcomes. European Radiology. 2025.
- Statistical considerations for repeatability and reproducibility of quantitative imaging biomarkers. BJR Open.
Claim / Evidence / Limitation
Claim
MRI研究の必要nは、研究の問い、効果量、測定ノイズ、評価指標、外部検証の有無から決まる。
Evidence
臨床MRI研究のn数調査、fMRI報告レビュー、radiomicsメタリサーチ、repeatability/reproducibilityの統計的考え方。
Scope
MRI研究者向けの公開教育用概説。正式なpower解析や統計解析計画書ではない。
Limitation
疾患頻度、施設差、読影者数、欠測、脱落、多重比較、モデル選択、解析単位によって必要nは変わる。実研究では個別設計が必要。
Zettelkastenへ戻す問い
- 自分の研究の主要評価項目は、差、一致、診断能、予測、再構成精度のどれか。
- 必要nを決める時、検出したい差Δと測定ノイズσをどこから見積もるか。
- 対応ありデザインを使えるのに、独立2群として扱っていないか。
- Bland-AltmanやICCでは、点推定ではなく信頼区間の幅を見ているか。
- AI/radiomicsで、外部検証なしの高AUCを過大評価していないか。
- 4D Flowのunwrapping評価で、簡単なケースだけを集めていないか。